
In this article we will do static analysis on PDF documents, including analysis of embedded strings.
First of all you need to download the sample malicious PDF files and Yara Rules for the experiments from the resources section:
When we discover a malicious file, binary, or program using a threat hunting strategy, we are required to gather the artifacts from those items and then conduct a search throughout our whole environment to look for any probable evidence of harmful activity.
This method is often carried out by analyzing the contents of the files, extracting Indicators of Compromise (IOCs) from those files, and then searching for any hits or matches in either the entire environment or the crown jewels, depending on the technique you have chosen.
The creation of Yara rules to search for artifacts, the utilization of the Mandiant IOC collector to save various IOCs with AND/OR conditions, and the utilization of Redline to search for the IOCs collected by the Mandiant IOC collector within a disk or memory are just some of the many tools that can assist us in this regard.
The analyst must collect every piece of information that may be utilized to detect malicious software when undertaking malware analysis.
Among the approaches is the application of Yara rules. In this section, I will discuss Yara rules and how to utilize them to identify malware.
Yara is an open-source tool that assists malware researchers to identify and classify malware samples by looking for certain characteristics.
Yara rules classify and identify malware samples by creating descriptions of malware families based on textual or binary patterns. We can use Yara rules to define text or binary patterns that will match a file or component of a file to quickly find malicious files.
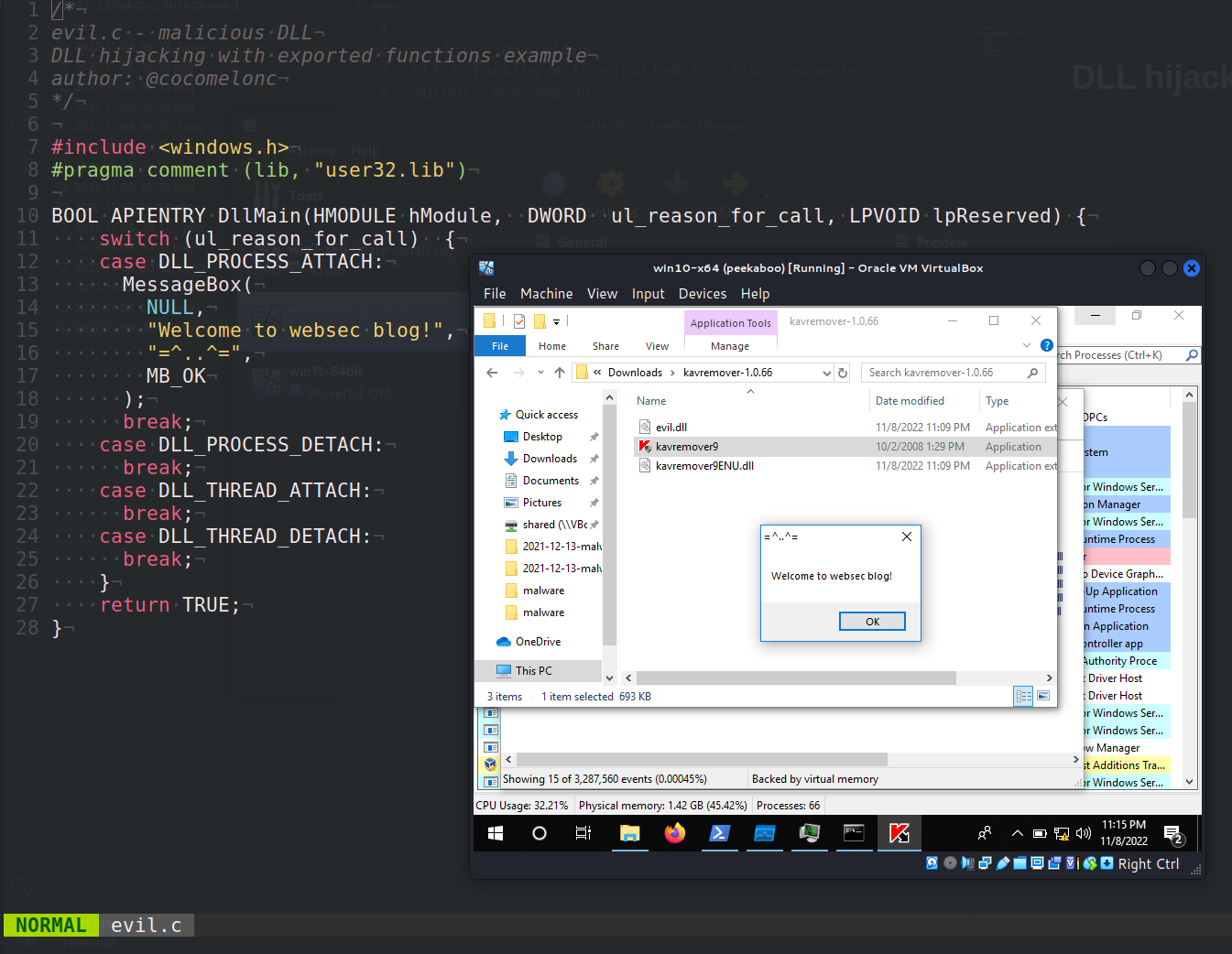
Let’s discover how to use Yara rules to discover malware. For simplicity, we use "malware" from DLL hijacking logic as an example:
/*
evil.c - malicious DLL
DLL hijacking with exported functions example
author: @cocomelonc
*/
#include <windows.h>
#pragma comment (lib, "user32.lib")
BOOL APIENTRY DllMain(HMODULE hModule, DWORD ul_reason_for_call, LPVOID lpReserved) {
switch (ul_reason_for_call) {
case DLL_PROCESS_ATTACH:
MessageBox(
NULL,
"Welcome to websec blog!",
"=^..^=",
MB_OK
);
break;
case DLL_PROCESS_DETACH:
break;
case DLL_THREAD_ATTACH:
break;
case DLL_THREAD_DETACH:
break;
}
return TRUE;
}
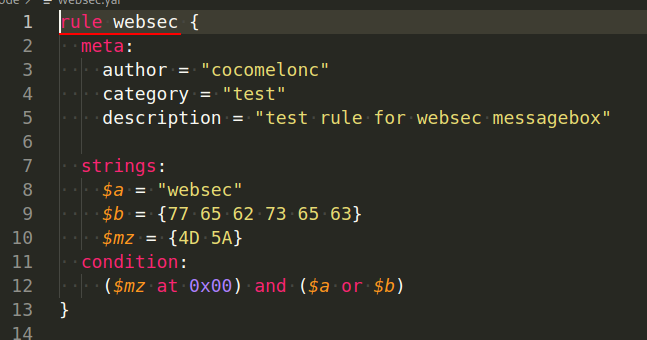
In Yara, each rule starts with a keyword rule followed by a rule identifier:
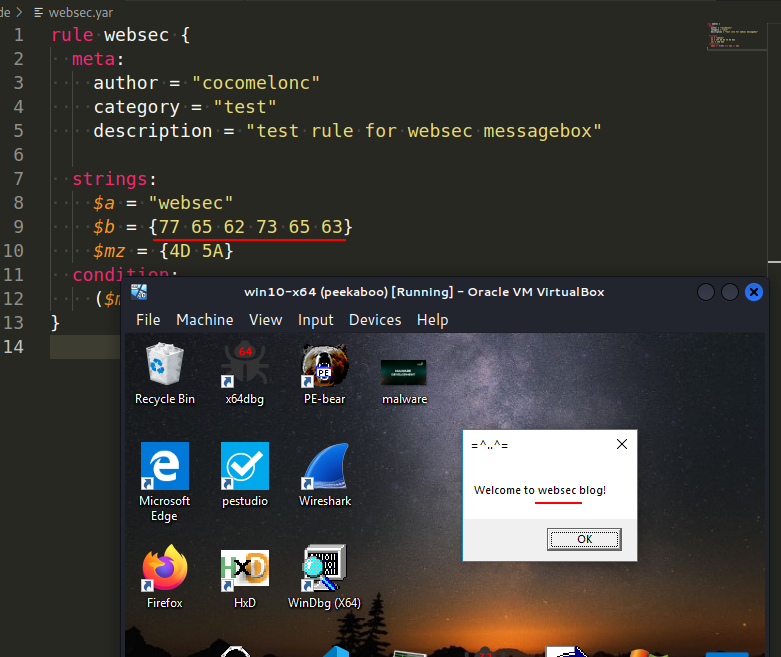
rule websec {
meta:
author = "cocomelonc"
category = "test"
description = "test rule for websec messagebox"
strings:
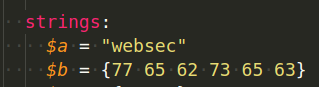
$a = "websec"
$b = {77 65 62 73 65 63}
$mz = {4D 5A}
condition:
($mz at 0x00) and ($a or $b)
}
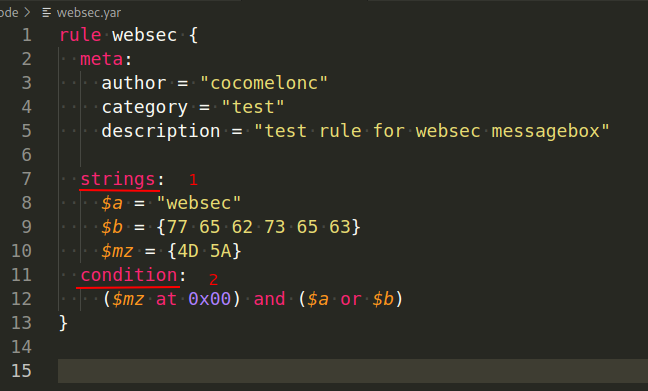
Rules are generally composed of two sections: string definition (1) and condition (2):
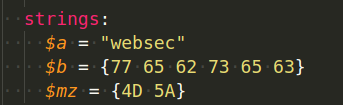
Strings can be specified in text or hexadecimal format, as seen in the example below:
The condition section is where the rule's logic is contained. This section must include a boolean expression indicating the conditions under which a file or process satisfies the rule:

In our test rule, which is called websec, we are looking for all files that contain the word websec. To do this, we set the websec as string and as hexadecimal format in the rules:

Let’s go to see everything in action. It’s pretty simple, just run:
yara websec.yar .
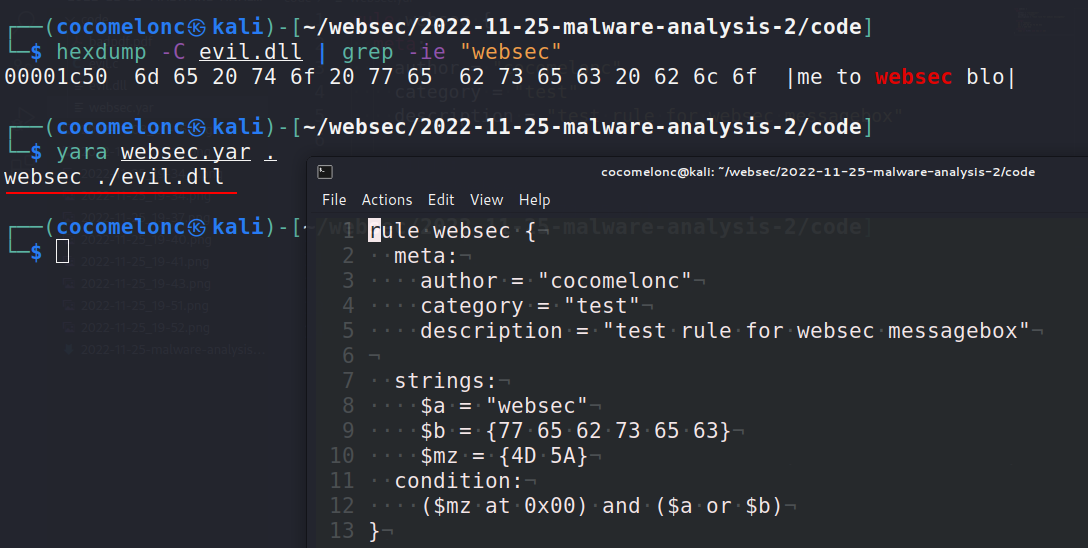
And it works as expected!
Now that you understand how the yara rule works, we will continue our static malware analysis.
So the Yara rules is rules continuing on the pattern for malicious code as well as binary, which you can use to scan files. It's just like an antivirus repository.
Adobe invented the PDF format in 1993 as a text-based structure that provides users with a dependable means to exhibit documents regardless of their operating system or software. PDF files may also contain photos, hyperlinks, video files, 3D objects, editable forms, and much more in addition to text.
-
Header - specifies the version number of the PDF.
-
The body - The document’s part that holds all of the information including text and other elements such as images, links, etc. The PDF file's body comprises many objects that can reference each other; the objects are of various types: Names –
/namebackslash followed by ASCII characters - setting a unique name. Strings -(text)its full syntax is a bit complex but what’s important is to know that it is enclosed in parentheses. Arrays - enclosed with square brackets([...])can contain other objects. Dictionaries - table of key and value pairs. The key is a name object and the value can be any other object. Enclosed within double angle brackets(<<...>>). Streams - contains embedded data structures like images (or code) which can be compressed. Streams represented by a dictionary that set the stream’s length with the key/Lengthand encoding/Filters. Indirect object - object that has a unique ID, the object starts with the keyboardobjand ends withendobjother objects can reference the object using its ID. For example a reference to object with ID3we would look like this:3 0 R -
Cross-reference table - Indicates the offset from the beginning of the file to each item so that the PDF reader may locate them without having to load the entire document (it can save time when opening big files).
-
Trailer - Provides information on the cross-reference table so that the PDF reader can locate the table and other items. PDF readers begin reading the document from the end, as seen in the sample below:
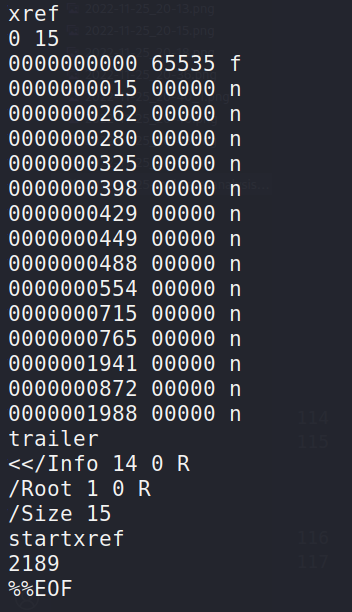 It is possible to modify PDF files such that additional items (such as cross-reference tables) be attached to the end of the file. Now that we understand the format, let's examine how attackers might utilize it to hide dangerous code.
It is possible to modify PDF files such that additional items (such as cross-reference tables) be attached to the end of the file. Now that we understand the format, let's examine how attackers might utilize it to hide dangerous code.
PDF documents may include a broad range of data formats (and not necessarily visible). Threat actors have complete control over the content of the files they transmit to victims, and they utilize the varied possibilities of the PDF format for assaults.
Many phishing attempts will feature links or pictures of buttons, vouchers, bogus CAPTCHAs, and more. The objective of these files is to send victims to sites under the control of the threat actors, where the next phase of the assault may be launched.
PDF files natively enable JavaScript, allowing attackers to construct files that execute scripts upon opening in order to steal information or download extra payload.
PDF streams may also be used by threat actors to distribute malware. Streams may include any sort of data (including scripts and binary files) and can be compressed and encoded, making it more difficult to spot code buried inside files. The compression method is defined using the /filter prefix (as mentioned in its part of the dictionary that describes a stream). A stream may have many filters.
There are several PDF readers in use; some are cross-platform, while others are based on web browsers; nonetheless, like with any other program, they have problems and vulnerabilities. Adobe PDF Reader alone has 91 vulnerabilities documented. Therefore, threat actors can create PDF files that attack vulnerabilities, allowing them to execute code and get access to the endpoint of the victim.
So we can start analysing our PDF sample. We start by doing a string's analysis of the PDF file. Just run:
strings -a ./badpdf.pdf
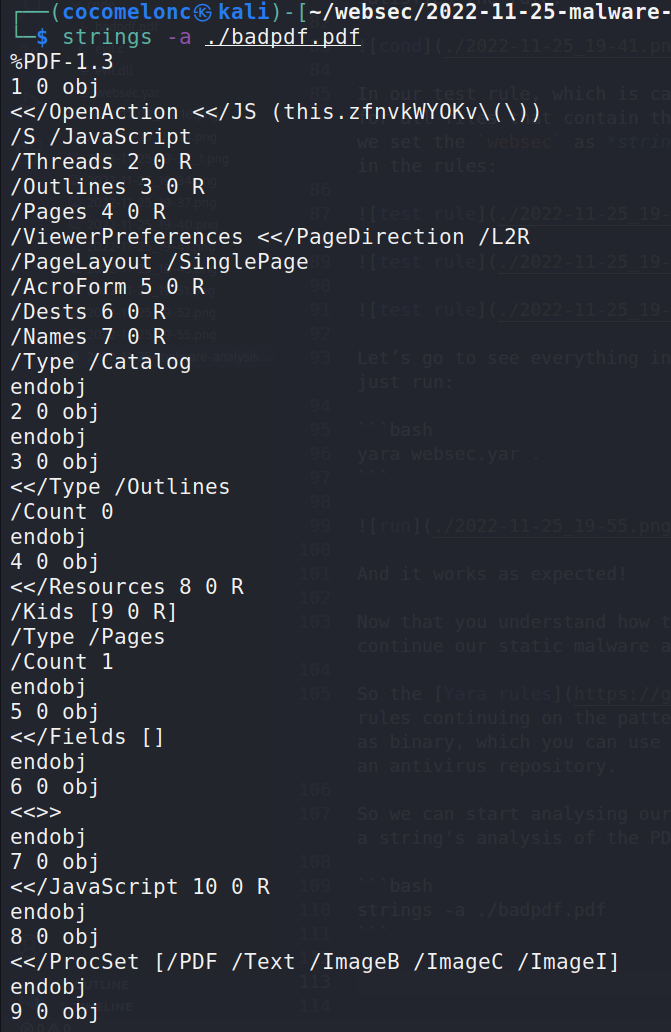
So as you can see, one of the strings which you found a %PDF-1.3, this is a header to indicate that this is a PDF file:
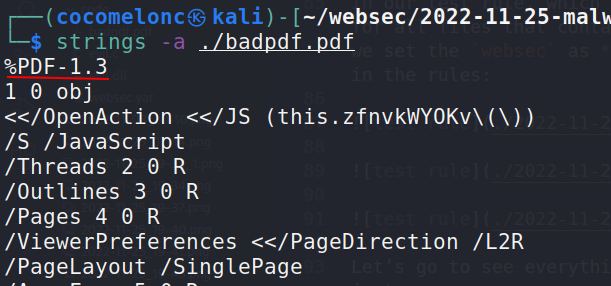
The second thing is important and significant a Javascript string:
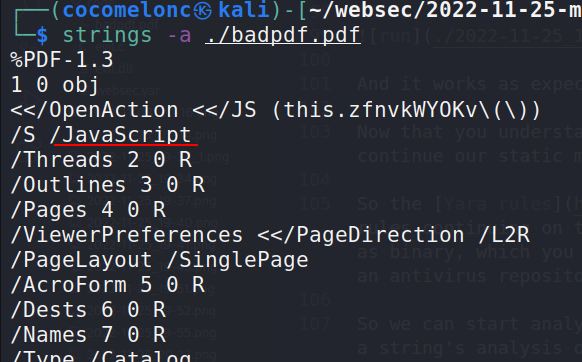
So what is this? This shows that our badpdf.pdf file has a embedded javascript is able to run javascript commands. And this is one common tactic used by malicious PDF documents using JavaScript to run something malicious.
The next operation we will execute is a search for encrypted strings; to do so, we will use the xorsearch command:
xorsearch badpdf.pdf http
So in this case, we want to see any encrypted URLs. So we are searching for this and we find that there are no encrypted strings.
Next, we will do a metadata analysis using the exiftool program.
exiftool badpdf.pdf
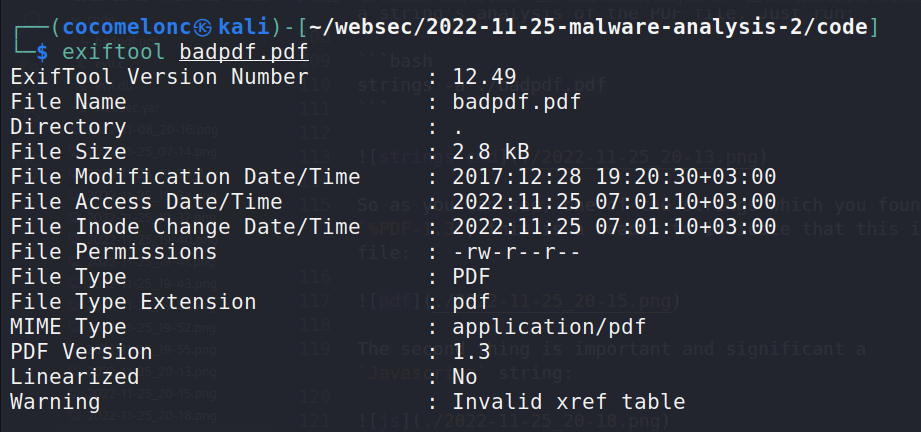 As you can see, file modification date is 2017 and MIME type is
As you can see, file modification date is 2017 and MIME type is application/pdf.
And next we are going to do yara scan via yara rules.
yara YARA_RULE_FILE TARGET_FILE

 Also, in order to suppress the warnings, we can put some additional parameters:
Also, in order to suppress the warnings, we can put some additional parameters:
yara -w -msg ~/malw/rules/index.yar badpdf.pdf
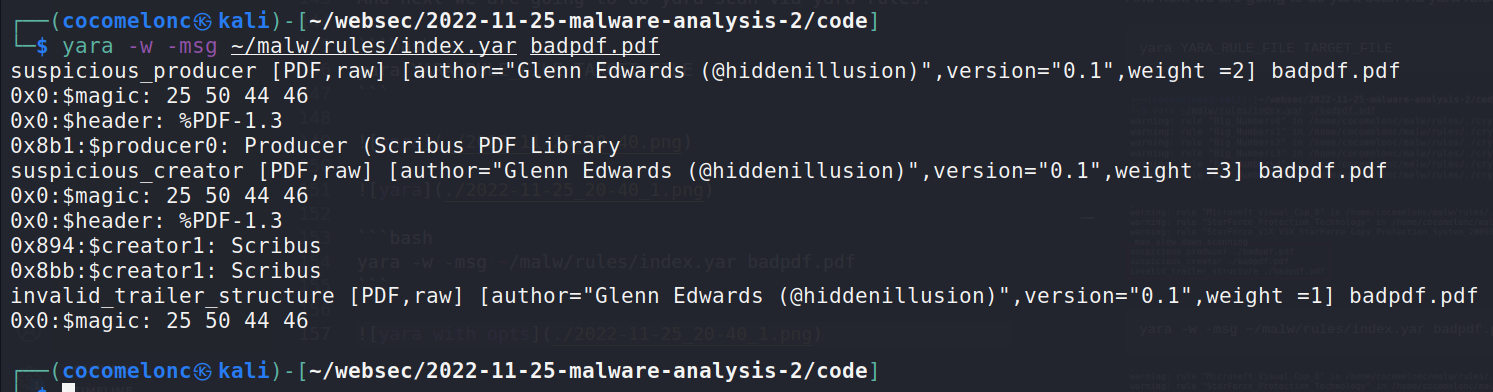
As you can see, first finding is suspicious_producer. the second one is suspicious_creator and third one is invalid_trailer_structure. Also we can use peepdf , a python tool that parses PDF files allowing us to get the types and content of each object. It will also color the object and highlight the objects that make the file suspicious, like the presence of javascript and embedded files.
https://github.com/Yara-Rules/rules
https://github.com/exiftool/exiftool
https://github.com/jesparza/peepdf